AWS Fault Injection Simulator (FIS) 触ってきた
はじめに
これで安全なアプリケーションになった!と思っていたが悲劇は起きた。
AWSのDynamoDBに障害が発生した
障害内容
この障害によりDynamoDBを始めとする20以上のAWSサービスが6時間以上の間使用できなくなりました。 社内システムなら5時間止まってもなんとかなるかもしれないが、SaaSとして事業を展開している企業にとっての5時間は想像以上にダメージが大きいと思います。
その時のNetflix
Netflixもこの大規模障害の影響を受けたものの、このようなリージョン単位の大規模障害に備えていたことから、重大な事態には至りませんでした。 Netflixでは常に障害発生ツールを使って障害対応の経験を積みアプリケーションを改善しています。これらをNetflixでは「ChaosEngineering」と呼んでいます。
AWS大規模障害を乗り越えたNetflixが語る「障害発生ツールは変化に対応できる勇気を与えてくれる」
What's ChaosEngineering
- ツールを使ってシステムに障害を注入する
- 障害: フェイルオーバーや特定インスタンスの謎の死など
- 障害注入は目的ではなく『手段』
- 『目的』はシステムの弱点を見つけて改善すること
- システムの安定性と回復力を強化する
起源は2011年にNetflixが開発したChaosMonkeyだと言われています。 Netflixを中心としたコミュニティがカオスエンジニアリングの原則を提唱しています。
なぜ最近よく聞くようになってきたのか
昨今、集中システム(モノリス)から分散システム(マイクロサービス)にトレンドが変わってきています。 マイクロサービスは「システムは落ちる」という前提でシステムを設計しているので、実際にシステムが落ちた時に影響を最小限に抑える必要があります。
| モノリス | マイクロサービス | |
|---|---|---|
| 特徴 | 全ての機能が1サーバに集中している | 機能ごとにサービスを分ける |
| 障害点 | 少ない(特定可能) | 多い(特定困難) |
| 求められる品質 | 落ちない | 落ちても自動回復 |
カオスエンジニアリングを行い、障害を早期に発見して被害を最小限に抑えることで、本番環境での障害発生に備えることができます。
Qiita: カオスエンジニアリングと聞いてカオスになった人必見
カオスエンジニアリングの基本原則
- 通常の動作を示すシステムの測定可能な出力として「定常状態」を定義することから始めます
- 定常状態はCPU使用率が〜。ではなくエラー率が〜%。のようにビジネスに直結する内容が良い
- この定常状態は、対照群および実験群の両方で継続すると仮定します
- サーバーのクラッシュ、ハードドライブの誤作動、ネットワーク接続の切断など、現実世界のイベントを反映する変数を導入します
- 対照群と実験群との間の定常状態の違いを調べることによって仮説を反証しようとします
【引用: カオスエンジニアリングの原則(検証におけるカオス)】
忘れられがちですが、可観測性がとても重要です。(要は定常状態の確認方法がしっかりしてること) 障害注入しても何が起きているか見えないのなら、改善につなげることはできず、ただカオスなだけになります。
要約するとこんな感じでしょうか。
「正常状態を可視化(モニタリングなど)して特定の障害注入を行った時に正常状態のままであるかを確認する。
詳細原則
- 定常状態における振る舞いの仮説を立てる
- システムが落ちると分かっててやるのはカオスなだけ
- 実世界の事象は多様である
- 本番環境で検証を実行する
- 継続的に実行する検証の自動化
- 影響範囲を局所化する
- 仮にシステムが落ちた場合に復旧させる必要があるため
【引用: カオスエンジニアリングの原則(詳細な原則)】
What's FIS
AWSリソースに対して障害注入を行いシステムの振る舞いを検証します。 エージェントレスで使えるので既に稼働中のシステムにも導入しやすいです。

実験テンプレート
実験の設計図です。これには、実験のアクション、ターゲット、および停止条件が含まれます。実験テンプレートを作成したら、それを使用して実験を実行できます。【引用: AWS FIS の概念】

アクション
- 注入する障害を定義する
- 注入する期間を定義する
- 複数ある場合は順次または並行を定義できる
ターゲット
停止条件
サポートしてるAWSリソース
2021/05/13時点では4種類+α(割愛)ですが今後増やしていく方針です
- Amazon EC2
- インスタンス再起動、停止、終了
- Amazon ECS
- Amazon EKS
- ノードグループのインスタンスを指定した割合終了させる
- Amazon RDS
- フェイルオーバー
- インスタンス再起動
実際にハンズオンで触ってきた
「EC2に対してFISを試してみる」という内容でした。
後半ではAutoScalingがちゃんと動くかを確認するための実験を行いました。
まず、ターゲット(今回はEC2インスタンス)を選択します。
特定の条件に合致するインスタンスを一定割合選択することもできます。
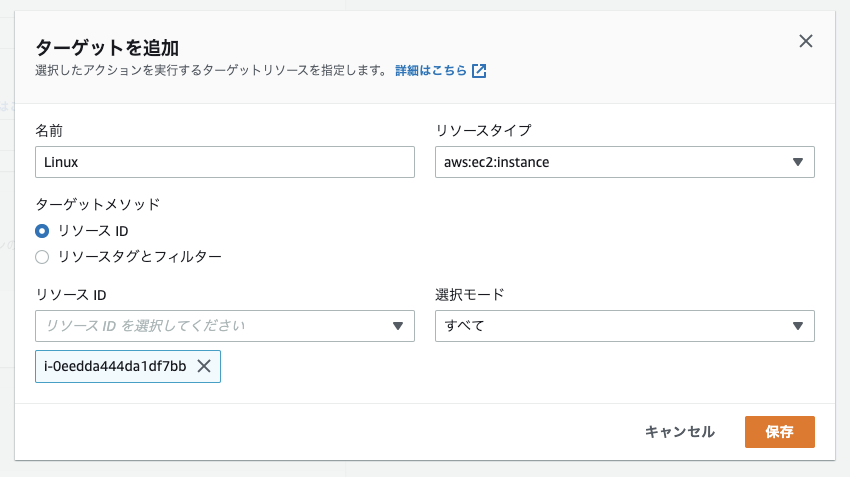
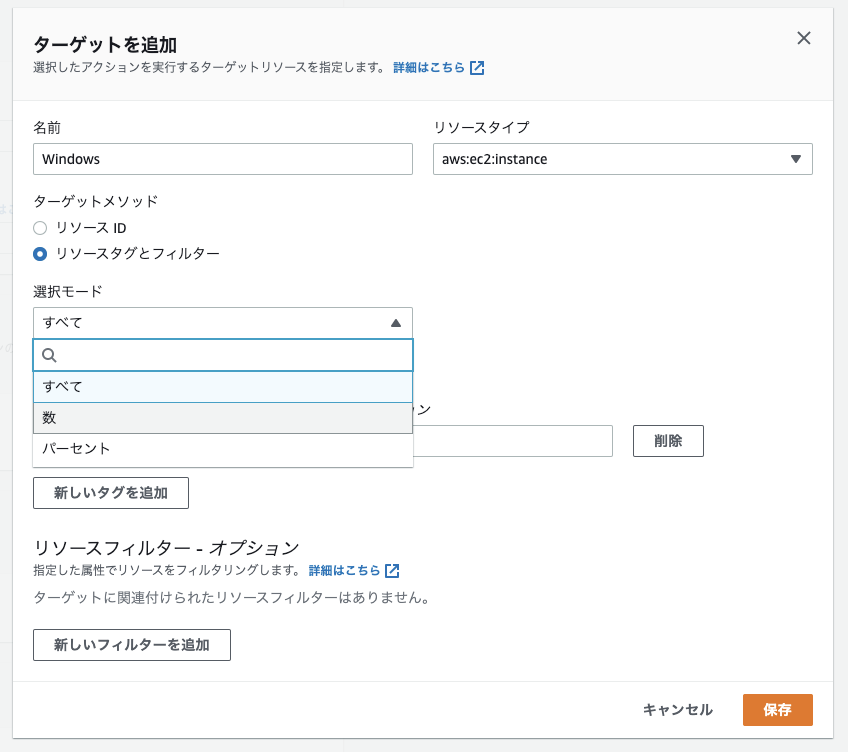
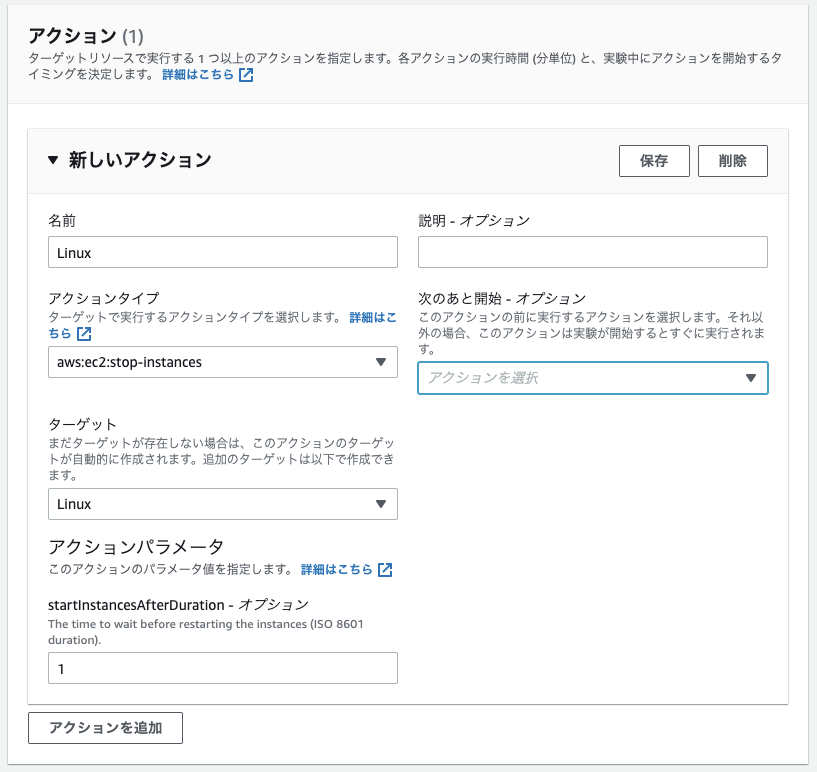
どんな障害(アクションタイプ)を発生させるかはこんな感じで設定します。
停止条件が登録されてないと確認画面が挟まります。
ハンズオンでは登録しませんでしたが、実際に本番環境で試すなら絶対設定しましょう!
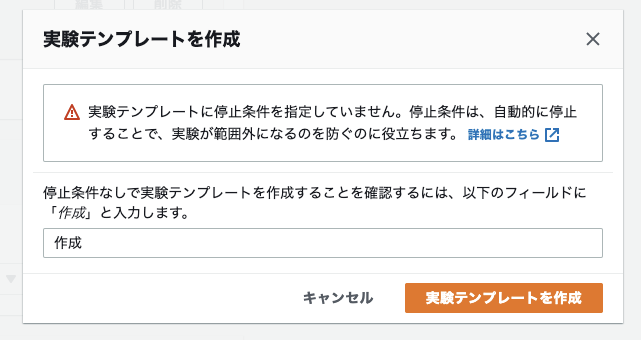
実験テンプレート登録完了!
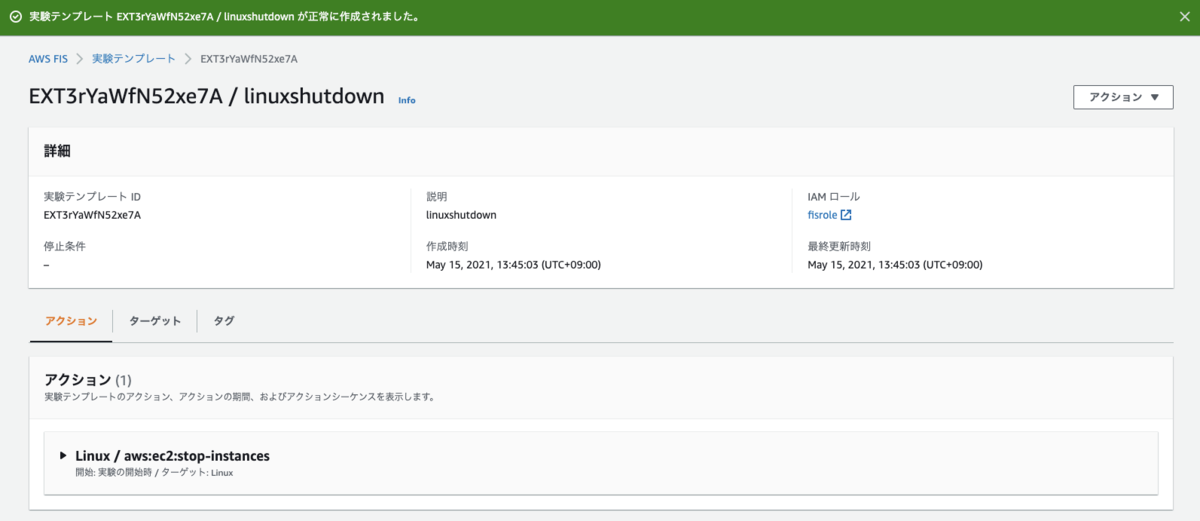
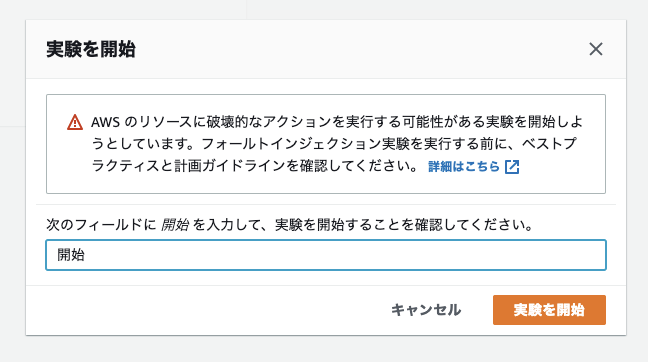
さぁ、実験を開始してみましょう。
本番を攻撃することになるのでココでも確認画面が挟まっています。
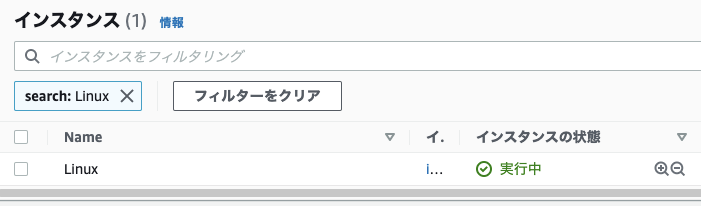
↑実験前(インスタンス起動してる)
↓実験開始(インスタンス停止)※ 1分後に復旧しました
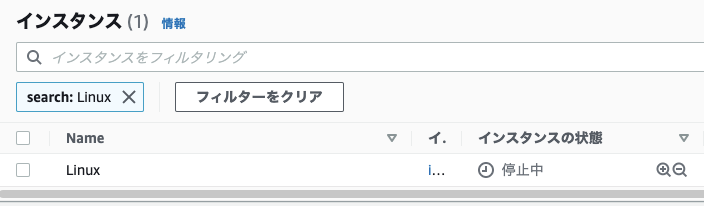
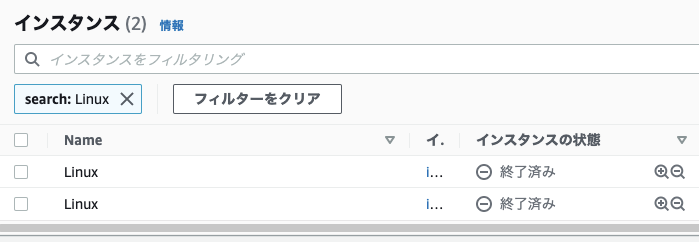
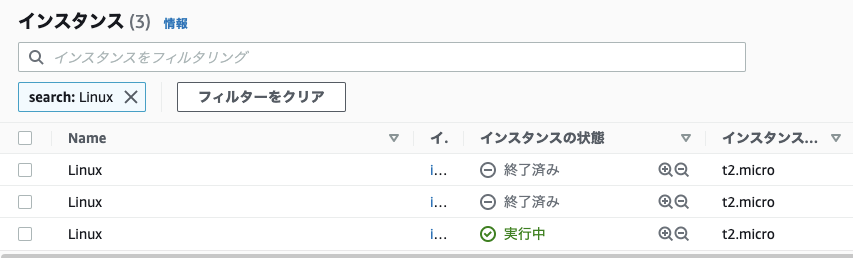
↑片方はAutoScalingを設定している状態で両方のインスタンスをTerminatedします。
↓AutoScalingが設定されているインスタンスは自動で復旧しました。
感想
事前に調べてから臨んだハンズオンだったので手を動かしながら知識の確認ができてて良かった。これからもやる
実際の現場に取り入れることができるのはいつになるか分からないが、その日のために未知の技術を体験して仕入れることができたのは非常に大切だと思いました。
現在はFISがサポートしているサービスは多くありませんが、今後増えていくと公言されているので楽しみです!
こんな怖いことを本番環境で実行している会社があると思うと.....色々な意味を込めて「スゴイ」の一言です。
参考にさせていただきました